
Data Protection by Design in Mendix
Waarom discipline geen controlemechanisme is
Leestijd: ±8 minuten
1. Introductie
Hoeveel van jullie hebben het afgelopen jaar een kopie van productie op je laptop gehad? Geen strikvraag. Gewoon nieuwsgierigheid. De kans is groot dat het antwoord niet nul is.
Productie data is namelijk bijzonder behulpzaam. Ze bevat echte klanten, echte randgevallen, echte inconsistenties; precies de dingen die in een synthetische dataset altijd nét ontbreken. En dus kopiëren we. Meestal met de beste bedoelingen, en een gezonde dosis onderdrukking van ons geweten. Dat is op zichzelf niet vreemd; het is efficiënt en vaak de snelste manier om een probleem te begrijpen. De natuurkunde kent ook weinig experimenten zonder meetdata.
Maar dan volgt een reeks vragen:
- Welke data is eigenlijk gevoelig?
- Welke attributen bevatten persoonsgegevens, direct of indirect, of bevatten bedrijfsgevoelige informatie?
- Hoe anonimiseer of bescherm je die gegevens?
- Wat doe je met referenties en afgeleide waarden?
- Hoe weet je dat je niets over het hoofd ziet?
- En als je dit morgen opnieuw zou moeten doen, zou je exact hetzelfde resultaat krijgen?
In de praktijk worden deze vragen zelden expliciet gesteld. De focus ligt op het reproduceren van de bug of het afronden van de user story; niet op het formaliseren van een structurele aanpak voor gegevensbescherming. Dan wordt bescherming van gevoelige data geen eigenschap van het model, maar een handmatige correctie achteraf.
2. De randvoorwaarden
Als bescherming van gevoelige data een volwassen ontwerpaspect moet zijn, dan moet zij aan een aantal voorwaarden voldoen:
1. Zij moet inzichtelijk zijn. Keuzes over gevoelige attributen moeten expliciet en zichtbaar onderdeel zijn van het ontwerp, niet impliciet verstopt in scripts of in hoofden.
2. Zij moet voorspelbaar zijn. De beschermingslogica moet controleerbaar en reproduceerbaar zijn. Determinisme kan een bewuste ontwerpkeuze zijn, maar is geen vereiste; toeval is dat evenmin.
3. Zij moet consistent toepasbaar zijn over omgevingen. Wat in de ene omgeving wordt uitgevoerd, moet in een andere identiek kunnen worden herhaald.

Wanneer er geen mechanisme is dat deze voorwaarden faciliteert of afdwingt, blijven zij afhankelijk van discipline. En discipline is omgekeerd evenredig met projectdruk.
3. Het model
Als discipline geen garantie is, moet de structuur het werk doen. En in een Mendix applicatie begint die structuur bij het domeinmodel, de formele beschrijving van de werkelijkheid. Entities definiëren wat er bestaat. Attributen definiëren welke eigenschappen relevant zijn. Bescherming van gevoelige data kan dan niet buiten het model blijven staan; zij moet daarin expliciet worden vastgelegd.
Dat betekent dat voor elke entity en voor elk attribute een keuze wordt gemaakt. Wordt de waarde behouden, gewist of vervangen? Geldt dit altijd of alleen onder bepaalde voorwaarden? Deze keuzes zijn geen technische details, maar beleidskeuzes. Ze bepalen hoe een organisatie omgaat met gevoelige informatie.
Hier ligt het fundamentele voordeel van een modelgedreven aanpak. Door het domeinmodel te spiegelen in runtime met behulp van ModelReflection ontstaat een gestructureerd overzicht van alle entities en attributen. Op basis daarvan kan per attribute een beschermingskeuze worden vastgelegd. Niet verspreid over scripts, maar centraal en inzichtelijk.
Die configuratie kan bovendien worden geëxporteerd naar JSON en in andere omgevingen worden toegepast. Daarmee wordt bescherming niet alleen een technische implementatie, maar een expliciet beleid dat overdraagbaar en bespreekbaar is.
Het resultaat is een verschuiving van IT oplossing naar business instrument. Stakeholders kunnen zien welke keuzes zijn gemaakt: welke data wordt behouden, welke wordt gewist, welke wordt gegenereerd.
Het vermijden van deze keuzes vereenvoudigt wellicht het gesprek, maar niets is zo hardnekkig als de werkelijkheid.
4. De uitvoering
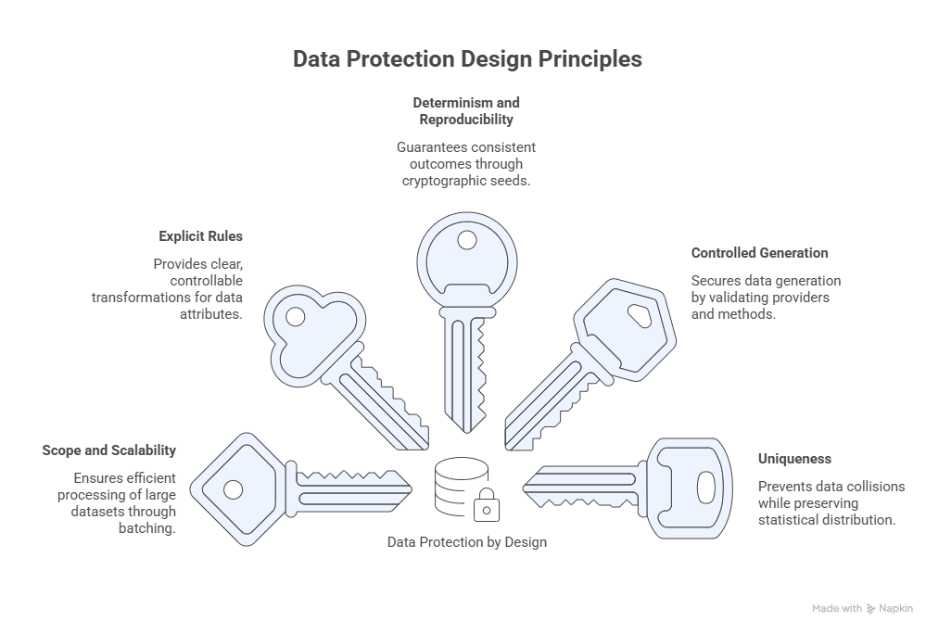
De keuzes die in het model worden vastgelegd, zijn pas waardevol wanneer zij ook systematisch kunnen worden toegepast. Bescherming mag geen losse handeling zijn; zij moet als mechanisme functioneren. Dit mechanisme is opgebouwd rond vijf ontwerpprincipes: scope en schaalbaarheid, expliciete regels, determinisme, gecontroleerde generatie en uniekheid.
We gaan nu kort de techniek in. Voor sommige lezers is dit een moment om hun koffie bij te vullen en weer bij ons te voegen in H5.
4.1 Scope en schaalbaarheid
De uitvoering start met een optionele XPath-scope per entity. Op basis hiervan wordt eerst het totale volume vastgesteld via een geaggregeerde count, daarna volgt verwerking in batches. Batching met offset en batchgrootte voorkomt geheugenpieken en maakt grootschalige vernieuwing van test- of acceptatiedata beheersbaar.
4.2 Expliciete regels
De configuratie in het model wordt vertaald naar een uitvoermodel via RuleTypes. Per attribute wordt expliciet gekozen voor een strategie zoals:
- KEEP
- CLEAR
- FIXED
- HASH
- GENERALIZE
- GENERATE
Elke RuleType correspondeert met een concrete, controleerbare transformatie. Er is geen impliciete “best guess”. Een ontbrekende of ongeldige configuratie leidt tot een expliciete fout in plaats van stille afwijking.
4.3 Determinisme en reproduceerbaarheid
Determinisme is een bewuste ontwerpoptie. Wanneer een rule deterministisch is, wordt een seed berekend op basis van stabiele input, zoals attributenaam en oorspronkelijke waarde, gecombineerd met een salt.
De seed wordt cryptografisch afgeleid via SHA-256 en teruggebracht tot een long. Daarbij wordt length-prefixing gebruikt om ambiguïteit in samengestelde inputs te voorkomen.
Het resultaat is idempotentie: dezelfde input, dezelfde configuratie en dezelfde salt leveren dezelfde uitkomst op.
4.4 Gecontroleerde generatie
Voor gegenereerde waarden wordt een gecontroleerde routinglaag gebruikt bovenop Datafaker. Zowel native expressies als call-style invocaties worden ondersteund, maar altijd binnen guardrails.
Provider- en methodenamen worden gevalideerd, risicovolle methoden worden geblokkeerd en alleen veilige return- en parametertypes worden geaccepteerd. Hiermee wordt voorkomen dat een configuratieveld verandert in een generieke Java-invocation engine.
4.5 Uniekheid
Uniekheid wordt niet blind afgedwongen. Voor String-achtige attributen wordt een gecontroleerde strategie toegepast om botsingen binnen een batch te voorkomen, zonder globale state of externe opslag.
Daarnaast kan bestaande data bucket-gebaseerd worden geherverdeeld via shuffling, optioneel deterministisch. Hiermee blijft de statistische distributie behouden terwijl individuele waarden niet meer herleidbaar zijn.
5. De context
De bovenstaande aanpak hebben wij bij MxBlue vertaald naar een Mendix-module: DataProtection. De module is geen universele oplossing voor alle vormen van gegevensbescherming. Dat zou verdacht zijn. Zij is bedoeld voor situaties waarin data buiten productie wordt gebruikt en waarbij expliciete, modelgedreven keuzes nodig zijn.
De module is met name geschikt wanneer:
- productie data wordt ververst naar test of acceptatieomgevingen
- realistische maar niet herleidbare data nodig is voor demo of validatie
- subsets van data gecontroleerd moeten worden gedeeld met partners
- pseudonimisering nodig is voor analyse zonder het volledige productieprofiel te behouden
- organisaties transparantie willen creëren over gemaakte beschermingskeuzes richting business en stakeholders
In deze situaties voegt de module structuur toe waar anders discipline het werk zou moeten doen.
Er zijn echter ook situaties waarin deze module niet de juiste oplossing is. De module is niet bedoeld wanneer:
- het doel is om data in productie zelf te beveiligen tegen ongeautoriseerde toegang
- encryptie of access control moet worden vervangen
- juridische interpretatie van regelgeving centraal staat
- cryptografische anonimisatie vereist is
- consent management moet worden ingericht
In deze gevallen ligt de oplossing elders in de architectuur. De module richt zich op gecontroleerde transformatie van data buiten productiecontext.
6. Conclusie
Het probleem dat hier is beschreven is concreet. Productie data wordt gekopieerd. Gevoelige informatie moet worden aangepast. Zonder expliciet mechanisme gebeurt dat ad hoc.
De DataProtection module biedt daar een oplossing voor. Zij maakt beschermingskeuzes zichtbaar in het model, maakt ze overdraagbaar tussen omgevingen en past ze systematisch toe op data. Daarmee wordt een kwetsbare handmatige stap vervangen door een reproduceerbaar mechanisme.
Wie productie data buiten productie gebruikt, heeft een gestructureerde manier nodig om die data aan te passen. Deze module voorziet daarin.
Auteur: Stephan Wolbers – Head of Technology & Innovation MxBlue|SUPERP


