
Data Protection by Design in Mendix
Why discipline is not a control mechanism
Reading time: ±8 minutes
1. Introduction
How many of you have had a copy of production on your laptop in the past year? No trick question. Just curiosity. Chances are that the answer is not zero.
Production data is particularly helpful. It contains real customers, real edge cases, real inconsistencies; exactly the things that are always just missing in a synthetic dataset. And so we copy. Usually with the best intentions, and a healthy dose of suppression of our conscience. That in itself is not surprising; It is efficient and often the fastest way to understand a problem. Physics also has few experiments without measurement data.
But then follows a series of questions:
- Which data is actually sensitive?
- What attributes contain personal data, directly or indirectly, or contain business-sensitive information?
- How do you anonymize or protect that data?
- What do you do with references and derived values?
- How do you know that you are not overlooking anything?
- And if you had to do this again tomorrow, you would get the exact same result?
In practice, these questions are rarely asked explicitly. The focus is on reproducing the bug or finalizing the user story; not on formalising a structural approach to data protection. Then the protection of sensitive data does not become a feature of the model, but a manual correction afterwards.
2. The conditions
If protection of sensitive data is to be a mature design aspect, it must meet a number of conditions:
1. It must be transparent. Choices about sensitive attributes should be an explicit and visible part of the design, not implicitly hidden in scripts or in heads.
2. It must be predictable. The protection logic must be verifiable and reproducible. Determinism can be a conscious design choice, but it is not a requirement; Nor is that a coincidence.
3. It must be consistently applicable across environments. What is performed in one environment must be able to be repeated identically in another.

When there is no mechanism that facilitates or enforces these conditions, they remain dependent on discipline. And discipline is inversely proportional to project pressure.
3. The model
If discipline is not a guarantee, the structure must do the work. And in a Mendix application, that structure starts with the domain model, the formal description of reality. Entities define what exists. Attributes define which properties are relevant. Protection of sensitive data cannot remain outside the model; it must be explicitly laid down in it.
This means that a choice is made for each entity and for each attribute. Will the value be preserved, erased or replaced? Does this always apply or only under certain conditions? These choices are not technical details, but policy choices. They determine how an organization handles sensitive information.
This is where the fundamental advantage of a model-driven approach lies. By mirroring the domain model in runtime using ModelReflection, a structured overview of all entities and attributes is created. Based on this, a choice of protection can be made for each attribute. Not spread over scripts, but central and insightful.
This configuration can also be exported to JSON and applied in other environments. This makes protection not just a technical implementation, but an explicit policy that is transferable and negotiable.
The result is a shift from IT solution to business instrument. Stakeholders can see which choices have been made: which data is retained, which is deleted, which is generated.
Avoiding these choices may simplify the conversation, but nothing is as persistent as reality.
4. The implementation
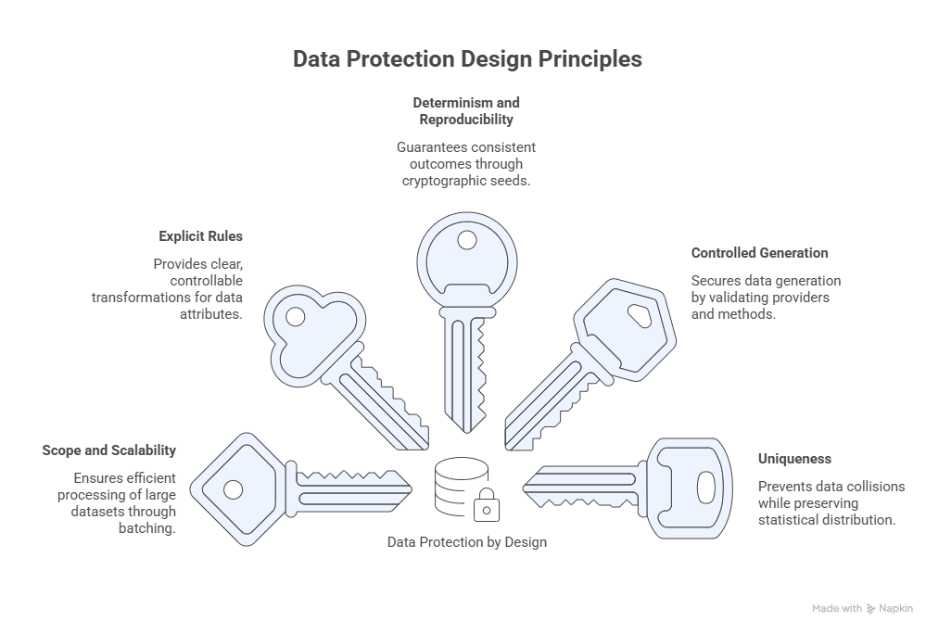
The choices that are recorded in the model are only valuable if they can also be applied systematically. Protection should not be a separate act; it must function as a mechanism. This mechanism is built around five design principles: scope and scalability, explicit rules, determinism, controlled generation and uniqueness.
We will now briefly go into technology. For some readers, this is a moment to refill their coffee and rejoin us in Chapter 5.
4.1 Scope and scalability
The execution starts with an optional XPath scope per entity. Based on this, the total volume is first determined via an aggregated count, followed by processing in batches. Offset and batch size batching prevents memory spikes and makes large-scale refresh of test or acceptance data manageable.
4.2 Explicit rules
The configuration in the model is translated into an output model via RuleTypes. For each attribute, a strategy is explicitly chosen, such as:
- KEEP
- CLEAR
- FIXED
- HASH
- GENERALIZE
- GENERATE
Each RuleType corresponds to a concrete, controllable transformation. There is no implied “best guess”. A missing or invalid configuration will result in an explicit error instead of silent deviation.
4.3 Determinism and reproducibility
Determinism is a conscious design option. When a rule is deterministic, a seed is calculated based on stable input, such as attribute name and original value, combined with a salt.
The seed is cryptographically derived via SHA-256 and reduced to a long. Length prefixing is used to avoid ambiguity in compound inputs.
The result is idempotence: the same input, the same configuration and the same salt produce the same outcome.
4.4 Controlled generation
Generated values use a controlled routing layer on top of Datafaker. Both native expressions and call-style invocations are supported, but always within guardrails.
Provider and method names are validated, risky methods are blocked, and only secure return and parameter types are accepted. This prevents a configuration field from turning into a generic Java invocation engine.
4.5 Uniqueness
Uniqueness is not blindly enforced. For String-like attributes, a controlled strategy is applied to avoid collisions within a batch, without global state or external storage.
In addition, existing data bucket-based can be redistributed via shuffling, optionally deterministic. This preserves the statistical distribution while individual values are no longer traceable.
5. The context
At MxBlue, we have translated the above approach into a Mendix module: DataProtection. The module is not a universal solution for all forms of data protection. That would be suspicious. It is intended for situations in which data is used outside of production and where explicit, model-driven choices are required.
The module is particularly suitable when:
- production data is refreshed to test or acceptance environments;
- realistic but non-traceable data is required for demo or validation;
- subsets of data should be shared with partners in a controlled manner;
- pseudonymization is necessary for analysis without maintaining the full production profile;
- organisations want to create transparency about protection choices made towards business and stakeholders.
In these situations, the module adds structure where discipline would otherwise have to do the work.
However, there are also situations where this module is not the right solution. The module is not intended when:
- the goal is to protect data in production itself against unauthorized access;
- encryption or access control must be replaced;
- legal interpretation of regulations is central to the;
- cryptographic anonymization is required;
- consent management must be set up.
In these cases, the solution lies elsewhere in architecture. The module focuses on controlled transformation of data outside of a production context.
6. Conclusion
The problem described here is concrete. Production data is copied. Sensitive information needs to be modified. Without an explicit mechanism, this is done ad hoc.
The DataProtection module offers a solution for this. She makes protection choices visible in the model, makes them transferable between environments and systematically applies them to data. This replaces a vulnerable manual step with a reproducible mechanism.
Anyone who uses production data outside of production needs a structured way to adjust that data. This module provides that.
Author: Stephan Wolbers – Head of Technology & Innovation MxBlue|SUPERP

